Overfitting and Underfitting: The Goldilocks Principle of Machine Learning


Just like Goldilocks in the classic fairy tale who wanted her porridge "not too hot, not too cold, but just right", machine learning models also need to be "just right" in terms of their complexity. Too simple, and they risk missing important patterns in the data- a problem known as underfitting. Too complex, and they might memorise the data instead of learning from it, leading to overfitting.
Understanding these concepts is important for anyone delving into machine learning. It would also benefit you if you often work closely with data scientists or machine learning engineers. Understanding these concepts can facilitate more effective communication and collaboration. I remember a situation where a data scientist in the AI precision team presented to a group of business personnel, and his content went over the head of the audience. It was pretty funny to see the blank faces. In this blog, let's take a closer look at one of the key machine learning fundamentals: overfitting and underfitting. I'll cover the following:
- What is Overfitting and Underfitting?
- The Role of Bias and Variance and its Relationship to Overfitting and Underfitting
- How to Deal with Overfitting and Underfitting?
What is Overfitting and Underfitting?
Overfitting and underfitting are terms used to describe the performance of machine learning models when they are too complex or too simple, respectively.
Overfitting happens when a model learns the training data too well. It gets so good at identifying patterns in the data it was trained on that it becomes bad at identifying patterns in new data. Imagine a student who memorises specific questions for an exam but fails to understand the underlying concepts. If the questions on the exam change slightly, the student will not perform well. This was me when I was learning how to read Nuclear Magnetic Resonance (NMR) spectroscopy as part of a drug discovery subject back in university. I was like the overfitted model. I did well on test papers (training data) but poorly on the exam(new, unseen data) 😅. I barely passed the subject, but to be fair, I wasn't the only one struggling. I think more than 50% of my class thought we all failed.
Underfitting is the opposite of overfitting. It is when the model is too simple to learn the underlying structure of the data. If a model is too simple, it might not be able to learn the important patterns in the data, much like trying to fit a straight line to a data set that is inherently nonlinear. An underfitted model performs poorly on both the training data and new, unseen data. It can be likened to a student who only reads a textbook summary and tries to take a test on the entire book. They will likely fail because they're missing key details.
Here are the two key points to remember:
The Role of Bias and Variance and its Relationship to Overfitting and Underfitting
Bias and variance are two important concepts to understand to better comprehend under and overfitting.
Bias refers to the gap between the value predicted by your model and the actual value of data. In the case of high bias, the predictions will likely be skewed in a particular direction away from the actual values.
Variance describes how scattered your predicted values are to each other. Let's look at this visual representation (Figure 1, sourced from Machine Learning For Absolute Beginners) to understand the bias and variance terms. Note that this isn't a machine learning visualisation, but I think it helps understand the two terms.
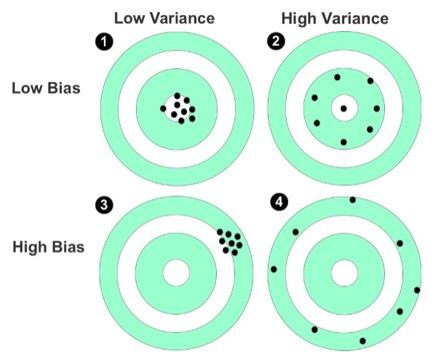
The bull's eye of the target represents the perfect prediction of data. The dots marked on the target represent individual predictions made by a model.
- The first target, with dots clustered near the center, shows low bias and high variance, indicating that the predictions are closely aligned with the actual values.
- The second target shows low bias but high variance; the predictions are near the bull's eye but spread out from each other.
- The third target represents high bias and low variance.
- The fourth target shows both high bias and high variance. If the model has high bias and high variance, then throw that model out. It's bad.
Bias and variance both contribute to prediction error, which we aim to minimise. Much like learning to ride a bicycle, the challenging part of machine learning is to balance bias and variance while ensuring a well-performed model.
So how are the two related to overfitting and underfitting?
Overfitting is associated with high variance and low bias. When a model overfits, it fits the training data too closely and captures the underlying patterns and the noise or random fluctuations in the data. As a result, the model becomes too complex, flexible, or flexible enough to memorise the training examples. This leads to a high variance because the model's predictions can vary significantly depending on the specific training data it was exposed to. In other words, the model is too sensitive to the fluctuations and noise in the training data.
On the other hand, underfitting is associated with high bias and low variance. An underfit model has high bias because it oversimplifies the relationship between the features and the target variable, resulting in poor performance. Since the underfit model is too simplistic, it typically shows low variance between its predictions don't vary much across different training sets.
Figure 2 (sourced from Machine Learning For Absolute Beginners) here brings together all the points covered beautifully:
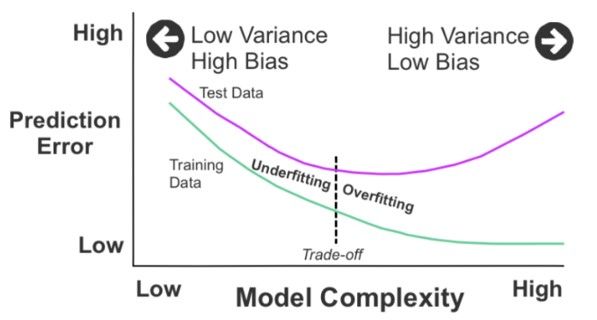
To summarise:
- Overfitting: low bias, high variance. The model is too complex and captures noise, resulting in high sensitivity to training data fluctuations.
- Underfitting: high bias, low variance. The model is too simplistic and fails to capture the underlying patterns, resulting in consistent but inaccurate predictions.
How to Deal with Overfitting and Underfitting?
Recall the two key takeaways:
• Underfitting occurs when your model is too simple for your data
• Overfitting occurs when your model is too complex for your data
So with underfitting, we want to add complexity, and with overfitting, we want to simplify. Here are the typical strategies:
- More simple or more complex model
- More Regularisation or Less Regularisation
- More features or Fewer features
More simple or more complex model
I've read that this is the easiest approach to dealing with underfitting and overfitting problems.
Underfitting: For an underfitting problem, increase the complexity of the machine learning model, which may mean switching to a more powerful model, like moving from logistic regression to a Support Vector Machines (SVM) model. If the model is already quite complex, and you need to make it more complex such as in the case of neural networks, it may mean adding more layers or connections between layers.
Just quickly for those who aren't familiar with neural networks. A neural network is a brain-inspired system that uses artificial neurons organised in layers and trained data to make intelligent decisions on new inputs. It encompasses various algorithms and techniques.
Overfitting: To simply the model, you do the opposite. You can change the algorithm from, say, for example, a deep neural network to a random forest. Have fewer layers, fewer artificial neurons, etc.
More Regularisation or Less Regularisation
Underfitting: Imagine you have a friend who loves playing video games but struggles to advance in difficult levels. They always play with many restrictions, like limited ammunition or health. These restrictions make it hard for them to progress and enjoy the game. To help them progress, we can ask the friend to relax some of the restrictions, allowing them to explore the game more freely and learn different strategies. In machine learning, if the model is underfitting, reducing the amount of regularisation can help it have more flexibility and adaptability to capture the underlying patterns effectively.
Overfitting: Imagine you are organising a painting competition, and one contestant always adds too many unnecessary details and decorations to their painting. Their artwork becomes cluttered and confusing. To guide them towards a cleaner and more focused painting, you provide them with some guidelines and restrictions, like using only a limited colour palette or specific brush strokes. Similarly, in machine learning, adding more regularisation techniques to the model's training process can help reduce overfitting by discouraging unnecessary complexity and focusing on essential features
More Features or Fewer Features
Overfitting: Imagine you are trying to bake a cake, and you decide to add every possible ingredient in your kitchen to the recipe. You end up with a chaotic and unappetising cake because some ingredients don't go well together. To make a tastier cake, you carefully select only the necessary and complementary ingredients. Similarly, in machine learning, if your model is overfitting, reducing the number of features or selecting only the most relevant ones can help avoid incorporating noise and irrelevant information, leading to better generalisation.
Underfitting: Imagine you are teaching a friend how to play a musical instrument, and you start with just one simple note. They quickly become bored because it lacks variety and excitement. To make the learning experience more engaging, you introduce them to different notes, scales, and melodies, providing a more comprehensive range of possibilities. Similarly, if your model is underfitting in machine learning, adding more features that capture relevant information can enhance the model's ability to learn and generalise accurately.
To wrap up, understanding the concepts of overfitting and underfitting, along with the roles of bias and variance, is important for anyone delving into machine learning or working closely with data scientists or machine learning engineers. These foundational principles are vital in developing models that are "just right" - not too simple, not too complex, but perfectly balanced to effectively learn from the data without falling into the traps of overfitting or underfitting.
I hope this blog has been a helpful guide to equip you better to navigate the complexities of machine learning and foster better collaboration with your data science team now that you know more of their language.Until next time, ciao~