What is Web Scraping, and What is it Used for?


Not long ago, I visited a few of my colleagues in Berlin, Germany. One of my colleagues told me about Pompe disease. It is a rare genetic disorder in which the body cannot break down complex sugars. Our conversation left me pondering all sorts of questions like how little I know about rare diseases, the definition of rare diseases, are rare diseases that rare, how many rare diseases have been identified, and are all rare diseases genetics disorders etc.
So driven to learn more about rare diseases and create more dashboards for my Tableau Public account (it looks rather naked at the moment), I decided to make a rare disease dashboard as one of my projects.
In the dashboard, I would like to show a list of the currently known rare diseases grouped by category. I managed to find a website that gives me this information. However, just the way the data is laid out on the website, it's a real pain in the backside of a task to copy and paste all the items to an Excel file. Instead of spending god knows how many hours manually copying and pasting, I think it's better that I use that time to invest in learning how to web scrape.
This is not my virgin go at web scraping. I tinkered with it last year. I used python and the BeautifulSoup library to scrape information on Archibald Prize winning artists and their works somewhat successfully. Seeing the computer scraping just over 100 pages of information in a few minutes was pretty epic. It completely knocked my socks off!
Honestly, I don't remember much about how I achieved it. The code might still be in my Google colab (short for colaboratory). I followed a video and applied the principles covered to the website I wanted to scrape. I didn't understand a lot of the things covered. I was merely following a "recipe", and you know what they say; the fact that you can follow a recipe doesn't mean you know how to cook. This time around, I've decided to take it more seriously and learn to cook.
Wow, that's a super long intro. I hope you're still with me. With all that said, this blog is opening a series on web scraping using python. In this opening blog, I'll cover the following:
- What is web scraping?
- Why web scrape?
- Is web scraping legal?
- Basics steps for web scraping
What is web scraping?
Web scraping – this term aptly captures what it means. I think it's a self-explanatory term. However, I know what appears obvious to some may not be to others. So I'll explain what it is. Web scraping refers to extracting data large amounts of data from websites in an automated way. I just learnt that there are different ways to scrape websites. What I had in mind was the self-built way where you write your code. But apparently, there are browser extension and software that does that.
Why web scrape?
In the intro, I explained why I web scrape. You can probably think of several applications of web scraping. Here are some common reasons why people scrape:
- compare prices on shopping websites, e.g. Amazon, Alibaba
- lead generation. Collect contact info about potential customers or clients
- research and development. Collect data to analyze
- and compile business intelligence such as financial data for market research etc
The list of things you can do with web scraping is almost endless.
Is web scraping legal?
From what I've read legally, web scraping against the wishes of a website is much of a grey area. Some websites explicitly forbid people from scraping their data, likely for two reasons:
- the website wants to protect its data
- making repeated requests to a website's server may use up bandwidth, slowing the website for other users and, in extreme cases, can cause the website to stop responding entirely.
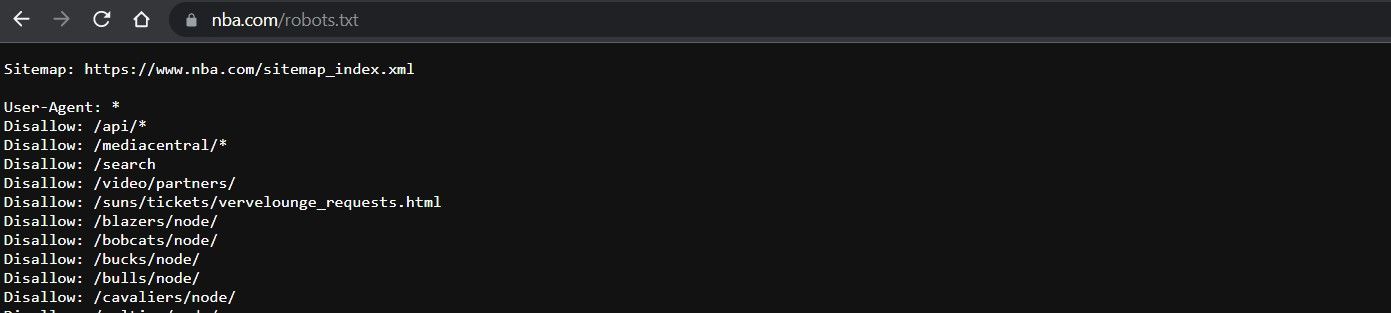
So, before we send out our scrapers, we should always check the target website's policy. How would you do that? To check if a website allows web scraping or not, we can look at the website's "robots.txt" file. We can locate this file by appending "/robots.txt" to the target URL. For example, my target website is the NBA website www.nba.com. To see the "robots.txt" file, the URL is www.nba.com/robots.txt. This is what you'll see:
Basic steps for web scraping
This is a high-level, non-technical overview of the steps involved in web scraping.
1. Identify your target URL(s)
This step probably sounds stupid, doesn't it? There are so many websites with similar information, so you must look around to figure out which website(s) to scrape. I spent a good few hours gleaning the web before I landed on the website I wanted to scrape the rare diseases list.
2. Inspect the page
Before starting any coding work, we must identify what the scraper we will create should scrape. How do you figure that out? You need to inspect the backend of the website. If you right-click anywhere on the front end of a webpage, it gives you the option to "inspect". Clicking on "inspect" will bring up the developer tool. Alternatively, on a Windows computer, you can click the F12 key. The developer tools show you the webpage's HTML and CSS code, which is what the scraper will read.
HTML and CSS are two languages that are important for websites. HTML stands for Hypertext Markup Language. It defines the structure of web pages. CSS stands for Cascading Style Sheets. It is a style sheet language used for describing the presentation of HTML. Put simply, it is used to prettify HTML. HTML on its own is a bit of an eye sore!
3. Identify the data to extract
Identify where the data you want to extract sits in the backend code. This requires you to understand a bit of HTML and maybe a smidge of CSS. Our goal is to identify the tags that enclose the information we want, e.g. "< div >" tags. Not to worry, we will spend some time on HTML if you don't know what I just said. Fortunately, we don't need to know HTML in-depth to be able to scrape websites. Some basic understanding is all we need.
4. Write the necessary code
The next step is writing the code to do the scraping, i.e. creating our scraper. I'll be using python. There are several python libraries we will need. What are libraries? Essentially, they are a set of useful functions other people have written. The beauty is that it eliminates the need for writing codes from scratch.
Web scraping will be pretty challenging if you don't have basic knowledge of python or any programming language. I recommend you first focus on learning the basics of python before tackling web scraping.
5. Execute the code
Once the code is written, we execute it and wait for the magic to happen! The scraper will request access to the website and extract and process the data.
6. Store the data
After we collect the relevant data, we will need to store it somewhere. We can write in our code where we want this data to be stored and in what format. Excel and CSV formats are the most common. Once the information is in the stored form we want, we can do all sorts of things with the data.
That's it for the opening blog on web scraping. Let's cover HTML next. It's an easy language to grasp the fundamentals. Until then, ciao~