Vector Embeddings & Vector Databases for Beginners

I've been delving into the world of databases in preparation for an upcoming project. I'll admit, I'm feeling both anxious and excited, more anxious, I would say, about it. I can sense self-doubt lurking in the shadows and have been actively working to conquer it. I see this project as a fantastic learning opportunity; however, I can't help but fear that it may potentially fail. I try not to let such thoughts get to me; as they say, you only fail if you don't learn something from the experience. So, I'm trying my best to embrace the challenge and see where it takes me.
While my upcoming project primarily revolves around traditional databases, my journey through self-education led me to a captivating concept: vector databases. The term "vector" isn't new to me. I first encountered it in physics, a subject I loved in high school. Interestingly, this term has etched itself so firmly into my head. And so, when I stumbled upon vector databases, my curiosity was instantly piqued.
I think storing data as high-dimensional vectors and having vector databases to manage these vectors are just bloody brilliant. I'm in awe! So, in this blog, I want to share with you what I've gleaned about vector databases, looking at the following points:
- What are Vector Embeddings and Vector Databases?
- Why The Rise in Popularity of Vector Databases?
- Use Cases of Vector Databases
What are Vector Embeddings and Vector Databases?
Before we define vector embedding and vector database, let's understand vector data. The word "vector" I learnt in physics is a mathematical term used to refer to quantity with magnitude and direction, such as 500 meters to the west is a vector. In the context of data science and information systems, vector has a slightly different meaning. It refers to an order list of values or attributes that describe the characteristics of something.
Let's look at an example. Consider a dataset of houses for sale, where each house's attributes are organized using vectors, and this is vector data.
• House 1: Vector representation [Price: $900,000, Bedrooms: 3, Bathrooms: 2, Land: 300sqm]
• House 2: Vector representation [Price: $150,000, Bedrooms: 4, Bathrooms: 3, Land: 400sqm]
• House 3: Vector representation [Price: $200,000, Bedrooms: 4, Bathrooms: 3, Land: 500sqm]
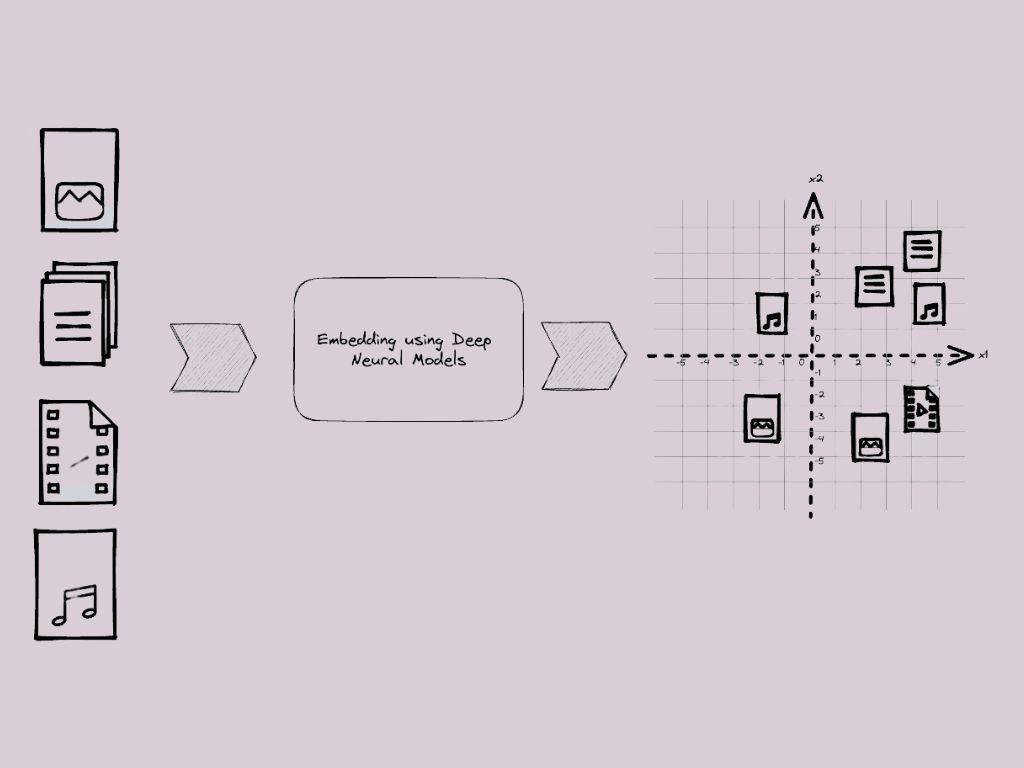
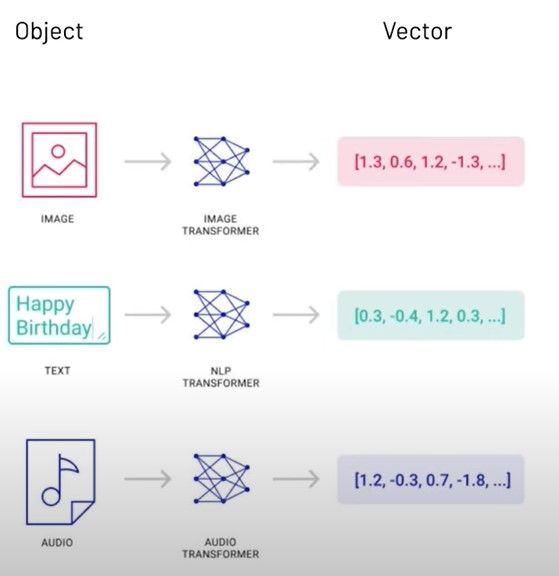
Now for vector embedding. Vector embedding is a way to convert words, sentences, and other data into numerical lists of numbers- these lists of number (vector) captures their meaning and relationships. Here is an illustration of vector embedding:
Vectors act as a multidimensional map to measure similarity. Let's consider a simple example. Imagine a 2D graph; the words "dog" and "puppy" often occur in similar contexts, so when we represent them in a vector, their vectors will be positioned closely together.
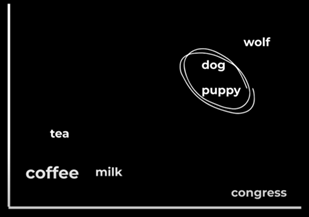
This example simplifies a much more complex reality. It's not uncommon to have tens and thousands of dimensions (not just 2D). This is so that it captures the intricate and multidimensional relationships between words, sentences and complex data like images etc. These vectors are created using machine learning algorithms that analyze large amounts of data to learn how to represent them in numerical values.
Once these vectors are created, it is stored in a database. A database filled with these vectors is known as a vector database. There are several use cases of vector databases, which will be covered shortly.
Why The Rise in Popularity of Vector Databases?
Vector Database is important in the age of AI. Over 80% of the data are unstructured, such as social media posts, videos, images, and audio data. We cannot easily store these in our traditional relational databases. The surge in unstructured data and AI demand innovation, and vector databases rise to the challenge.
Unlike traditional databases, which excel with structured data but falter with unstructured data, vector databases are tailor-made for the job. They leverage vector representations and machine learning techniques to store data flexibly, capturing relationships between data points in high-dimensional spaces.
Use Cases of Vector Databases
Vector databases have various use cases. Let's go over some of these use cases:
Equipping Large Language Models with Long-term Memory:
Large language models (LLMs) like GPT-3 or GPT-4 can benefit from vector databases to store and retrieve information for long-term memory. Instead of relying solely on their contextual understanding, these models can use vector databases to efficiently remember and access previously encountered information. This allows them to provide more contextually relevant responses and improve their performance in tasks that require retaining knowledge over extended periods.
Semantic Search:
Vector databases excel at semantic search, where the goal is to find results based on the meaning or context of a query rather than exact string matches. In this use case, documents, articles, or other textual data are represented as vectors. Users can input a query, and the database retrieves documents with vectors closest in meaning to the query vector. This enables more accurate and context-aware search results, making it valuable in applications such as information retrieval, content recommendation, and question-answering systems.
An example of semantic search we're all too familiar with is Google Search. When we search the phrase "stock price of apple" vs "calories of apple" " Google can figure out the first apple we're after is a company, and the second apple we're after is the fruit: apple.
Similarity Search for Images, Audio, or Video Data:
Beyond text, vector databases are highly useful for searching and retrieving similar content in non-textual data like images, audio, or video. Instead of relying on metadata or keywords, these databases use vector representations of the content. For example, in image search, you can input an image, and the database finds visually similar images by comparing their vector representations. This is crucial in applications like content recommendation, plagiarism detection, and content retrieval in multimedia archives.
Ranking and Recommendation Engine:
Vector databases can serve as powerful ranking and recommendation engines, particularly in e-commerce and content platforms. For instance, in an online retail setting, they can suggest products to customers based on their past purchases or preferences. By identifying the nearest neighbours in the vector space, the system can recommend items like those the customer has shown interest in. We've all experienced this when we shop on Amazon! This not only enhances user experience but also contributes to increased sales and engagement in platforms where personalization is key.
And that's a wrap! I hope you found this topic as captivating as I have. Before I bid adieu, I'd like to share a quick update. Starting today, I'll transition from a weekly blog post schedule to one every fortnight. This change will allow me to allocate extra time to a long-neglected personal project that's been calling for my attention. Your understanding and support mean a lot to me. Thank you for being part of my data adventure. 💕